
Projectors are registered to the cameras. This is the usual VIOSO way of calibrating a screen. The camera image gives us a way to relate projector pixels and map them to a content. This is what we call a content space. Literally, it is more like a content plane, as we use 2D coordinates for the transformation.
The main difference in Anyblend SIM is that we can introduce other content spaces because we know exactly where camera or projector pixels are pointing on the actual screen. This allows us to cast 3D coordinates to the camera’s pixels and enables us to do Observer views by re-projecting through a virtual camera or view pose.
If a model contains texture coordinates, we can build a new 2D content space from this. This gives us a way of warping/blending multiple registered cameras or do projection mapping.
A content space transformation describes the act of converting a camera scan to a custom content space (aka a virtual screen model) possibly with texture coordinates. We can go for two different approaches: Model and Markers or Smart test images.
Table of Contents
Matching a model with the screen
We need a scan from a pose registered camera and a model. Once we have registered every projector pixel with a camera pixel and the camera to the model, we can transform the scan based on the model.
If texture coordinates were provided, the content space gets converted, as well. After the scan, we work in the content space of the camera — we back-project a camera image on the screen, warped using the warping grid. We now replace the camera coordinates with the texture coordinates from the model. Now we can back-project a texture on the screen and do projection mapping. So if you would play your texture atlas, it fits to your screen, even if that screen is some object or façade.
The next points describe the steps using a pose-registered camera.
-
Camera content space translation
After, you can edit the camera content space. While warping, the view vector of the camera is transformed, so you actually adjust the camera pose and intrinsic parameters. You can use this feature to micro align multiple cameras or do minimal adjustments of the camera pose and intrinsic. -
Add VC to display geometry
This step is only necessary if you have done changes in content space translation. After that step, the VC is reset to “full screen” and all changes are applied to the mapping. -
Content space conversion
Use a model inside the camera viewport to generate a 2D content space from the model’s texture coordinates and generate a 3D map. The new content space is used from now on to distribute the content. Now we have assigned a 3D coordinate of the screen to every projector pixel and use this to calculate observer views or use dynamic eye-point warping.
Smart test images
What if we do not have camera intrinsic parameters or screen models? For flat, cylindrical, and spherical setups, we have developed a far easier way to register a projector to a screen. We need a test image that, once aligned to the screen, indicates the 3D coordinate implicitly!
Once the test image is positioned on the screen using the warping grid, and we know how to calculate these coordinates from the test image, we can transform them to the projectors.
So far there are 3 such conversions implemented:
- Camera to flat screen.
- Fisheye to spherical screen.
- Fisheye to cylindrical panorama.
But there is no limit in doing things that way. If necessary, we can implement these kind of conversions fast if there is a simple formula or a map to generate 3D coordinates from the test image. Even the content space is implicitly defined by the conversion method. The spherical conversion leads to a dome master content space commonly used by half domes i.e. planetariums, the cylindrical conversion to a panorama content space.
Calculate auto pose
It is hard to find the optimal pose for an IG channel. But once a scan has been converted and bears the 3D coordinate of every projector pixel, you can simply go to Calibration->Conversion tasks and select “Auto pose”. Select the channel you want to calculate an auto pose from. If you select multiple displays or (Super) Compound(s), a pose is calculated for every participating display.
Now just enter your observer’s eye-point (“sweet spot”) and press perform.
You’ll find the poses in Extras->Custom content spaces. They are named after the display from which they’re derived.
If a pose with that name already exists, it will be overwritten! So if you do not want to stick with the calculated poses, create some with different names.
Observer conversion
In simulation environments, we have to create an immersive experience for the user. Hence the “window” the user sees the simulated world through needs to be as big as possible. So we use power walls, curved screens, or domes to fill a person’s view to the maximum amount.
Whenever we need more than one flat image to transport, we have to go for multiple channels and poses. Clearly, we can render the virtual world from some virtual eye-point in every orientation and field of view. This is what we call a pose or a viewport. But how do we match our projection channel with that?

The projected image covers a part of the screen and we have to fill in the content. We know which 3D coordinate of the screen every projector pixel points to by registering the projector to the screen. So rendering the 3D coordinates of the projector by a viewport leads to a coordinate on the render plane.
Using the same relative pose for the IG to generate the image — we have the content to be filled in.
An observer conversion simply generates a lookup map to fill the projector pixels with the content from a rendered image based on the same viewport settings. Of course, we have to use a fixed eye-point in the real world towards the screen because it wouldn’t move. However, the eye-point and orientation in the virtual world may change. It only has to be the same for all channels (world transformation).
The hard thing about these conversions is finding the optimal pose to render from. See “Content space management” for further considerations.
To test a pose, you have to save a 3D converted to a new name. Remember, we need the original scan as base for an auto recalibration!
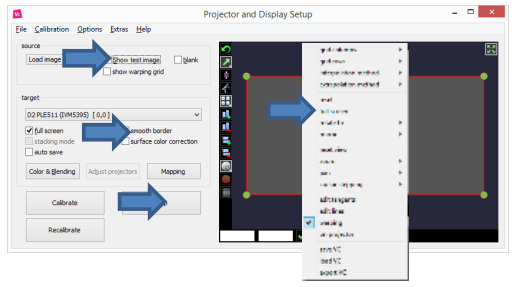
- Do observer conversion with matching pose.
- Start preview on that channel.
- Fullscreen the VC.
- Check “show test image”.
- Uncheck smooth border.
- If the projector stays black, you probably have the wrong pose.
- Look for problems like this:
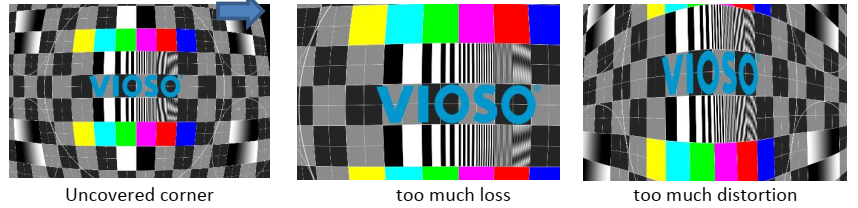
You can easily fix the first two problems by adjusting the viewport. The third problem can’t be solved in software. Consider changing the projector setup (i.e. use portrait mode) to get less distortion. Repeat the steps until the screen is optimally covered.